Contexts¶
As seen in the Introduction mdf deals with nodes which are structured into a directed acyclical graph (DAG) which are then lazily evaluated.
The structure of the code is what defines the DAG, but on its own the DAG has no
values, only the capability of computing values. The context
(MDFContext) is what contains the values at the nodes in the DAG
and so a node can only be said to have a value in a context.
There is one special node that is always present and is set when the context is
constructed, now(). This node represents the current time for all
computations in the context, and all values that are time-dependent reference
this node.
Multiple contexts can be constructed, and the same nodes can be evaluated in these different contexts to get diffent results with different starting values. Here’s a quick example
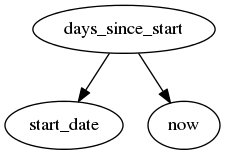
from mdf import MDFContext, evalnode, now
from datetime import datetime
start_date = varnode()
@evalnode
def days_since_start():
delta = now() - start_date()
return delta.days
# create two contexts
ctx1 = MDFContext()
ctx2 = MDFContext()
# set the date on each context (this is used by the 'now' node)
d = datetime(2011, 8, 9)
ctx1.set_date(d)
ctx2.set_date(d)
# set different start dates on the contexts
ctx1[start_date] = datetime(1970, 1, 1)
ctx2[start_date] = datetime(2000, 1, 1)
# the node days_since_start has a different value in ctx1 and ctx2
days1 = ctx1[days_since_start] # = 15195
days2 = ctx1[days_since_start] # = 4238
Setting Values¶
Values are set for nodes in a context using the MDFContext.set_value()
method or more commonly by indexing into the context with the node:
A = varnode()
ctx = MDFContext()
# set the value of A in ctx
ctx[A] = 100
# get the value A in ctx
a = ctx[A] # a == 100
Any node type can have a value set to it. Once a value is set for a node in a
context it is fixed until it’s changed again. Even if a node has dependencies
(e.g. an evalnode()) and its dependencies are changed the node won’t
be re-calculated if a value has explicitly been set.
Once a context has been created and any initial values have been set any available nodes can be evaluated. Node values can also be set in the context and when any dependent nodes are re-evaluated they will reflect those changes
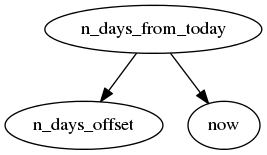
from mdf import MDFContext, evalnode, varnode, now
from datetime import datetime, timedelta
n_days_offset = varnode("n_days_offset")
@evalnode
def n_days_from_today():
offset = n_days_offset()
return now() + timedelta(days=offset)
# create the context and set the date
ctx = MDFContext()
ctx.set_date(datetime(2011, 8, 9))
# set the value of n_days_offset
ctx[n_days_offset] = 1
print ctx[n_days_from_today] # datetime.datetime(2011, 8, 10, 0, 0)
# update n_days_offset
ctx[n_days_offset] = 100
print ctx[n_days_from_today] # datetime.datetime(2011, 11, 17, 0, 0)
Overriding Nodes¶
As well as being able to set a node’s value in a context it is also possible to override a node itself in a context. For example, suppose you had the following graph
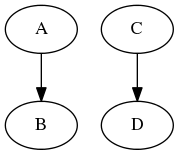
It’s possible to override node B with node C using the
MDFContext.set_override() method, or by setting the value on the
context for one node with another node:
from mdf import MDFContext, evalnode, varnode
B = varnode(default=10)
D = varnode(default=20)
@evalnode
def A():
return B() * 5
@evalnode
def C():
return D() * 10
ctx = MDFContext()
a = ctx[A] # a == 50
# override B with C
ctx[B] = C
a = ctx[A] # a == (B overriden with C) * 5
# == (D * 10) * 5 == 1000
# A now depends on C which depends on D
# so changing D changes A
ctx[D] = 2
a = ctx[A] # a == 100
The resulting graph (where := denotes overriden with) looks like this:
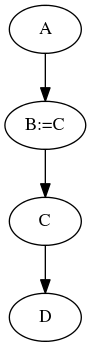
Any type of node can be overriden by any other type of node. This means that you
can override entire sub-graphs or add new sub-graphs where previously there was
just a single varnode().
Overriding nodes can be useful for unit testing. If you have a node that you don’t want to evaluate as part of a unit test it can be overriden with a mock node.
Shifted Contexts¶
As mentioned above, a node only has a value in a context. In some situations it’s useful to be able to evaluate a node in a context given another node is set to some value without modifying the context.
Consider the following DAG
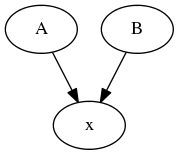
Suppose you want to evaluate A for all x in [1, 2, 3, 4, 5] but you
don’t want to actually affect any other values in the context. You could do
that by shifting the context and evaluating A on the shifted context:
from mdf import MDFContext, evalnode, varnode
from datetime import datetime
x = varnode()
@evalnode
def A():
return x() * 2
@evalnode
def B():
return x() * 3
ctx = MDFContext()
# set some value for 'x'
ctx[x] = 100
print ctx[A] # 200
print ctx[B] # 300
# calculate A[x=1,2,3,4,5] without modifying the context
for i in [1, 2, 3, 4, 5]:
shifted_ctx = ctx.shift({x : i})
print shifted_ctx[A] # 2, 4, 6, 8, 10
print ctx[A] # nothing's changed, still 200
print ctx[B] # nothing's changed, still 300
Shifting a context creates a new context with the shifted value set to a new value, but the shifted context is linked to the original context.
All values not dependent on the shifted value are still shared between the contexts. If you change one in one context it changes in all related contexts. This also means that the cached calculated values are also shared and so shifting a context can be more efficient than simply cloning it.
mdf provides a function shift() for use within a node function. It
returns the values of a node in multiple shifted contexts and can be used to
create new sub-graphs in the DAG, for example:
![digraph foo {
"sum(A: x=[1...5])" -> "A[x=1]"
"sum(A: x=[1...5])" -> "A[x=2]"
"sum(A: x=[1...5])" -> "A[x=3]"
"sum(A: x=[1...5])" -> "A[x=4]"
"sum(A: x=[1...5])" -> "A[x=5]"
"A[x=1]" -> "x=1"
"A[x=2]" -> "x=2"
"A[x=3]" -> "x=3"
"A[x=4]" -> "x=4"
"A[x=5]" -> "x=5"
"A" -> "x"
}](_images/graphviz-31b5498b7dd54bf4f10aa64f5a5979d2eafceb3b.png)
This relatively complicated looking DAG can be written by shifting A by
x:
from mdf import varnode, evalnode, shift
x = varnode()
@evalnode
def A():
return x() * 2
@evalnode
def sum_of_A():
all_As = shift(A, x, [1,2,3,4,5])
return sum(all_As)
This allows for code that behaves like sub-routines and loops but retains the DAG struture.
Shifting works with overriding nodes also. If the shift value is actually a node instance then the shifted node will be overriden by that node in the shifted context.